
Does More Thinking Really Make AI Smarter? Insights from Apple’s Research
If you’ve opened ChatGPT, Claude, or Gemini lately, you might have noticed a new button that shows the model’s “inner thoughts.” Click it and—voilà—you see a scroll of reasoning steps that supposedly prove the AI is being deliberate, almost human-like.
Does more “thinking” really make these models smarter? Apple’s research team just dropped a 50-page study tackling exactly that.
TL;DR: In medium complexity problems, LRMs perform better than LLMs, but they collapse to 0% accuracy in higher level complexity.
Understanding Large Language Models and Reasoning Models
Large language models (LLMs) achieved a significant milestone in 2024–25. Several commercial systems now expose deliberate chains-of-thought (CoT) during inference and label themselves as “Large Reasoning Models” (LRMs). Vendors claim these models reason more reliably, self-correct, and move us toward more general intelligence.
However, most leaderboard results between models depend on math or coding benchmarks that are susceptible to training data contamination. They also reveal little about how a model’s internal reasoning progresses as tasks become more challenging. This is where Apple’s research team fills the gap. They design a tightly-controlled experimental framework, assess five prominent LRMs, and reveal precise scaling limits.
The Puzzle Suite
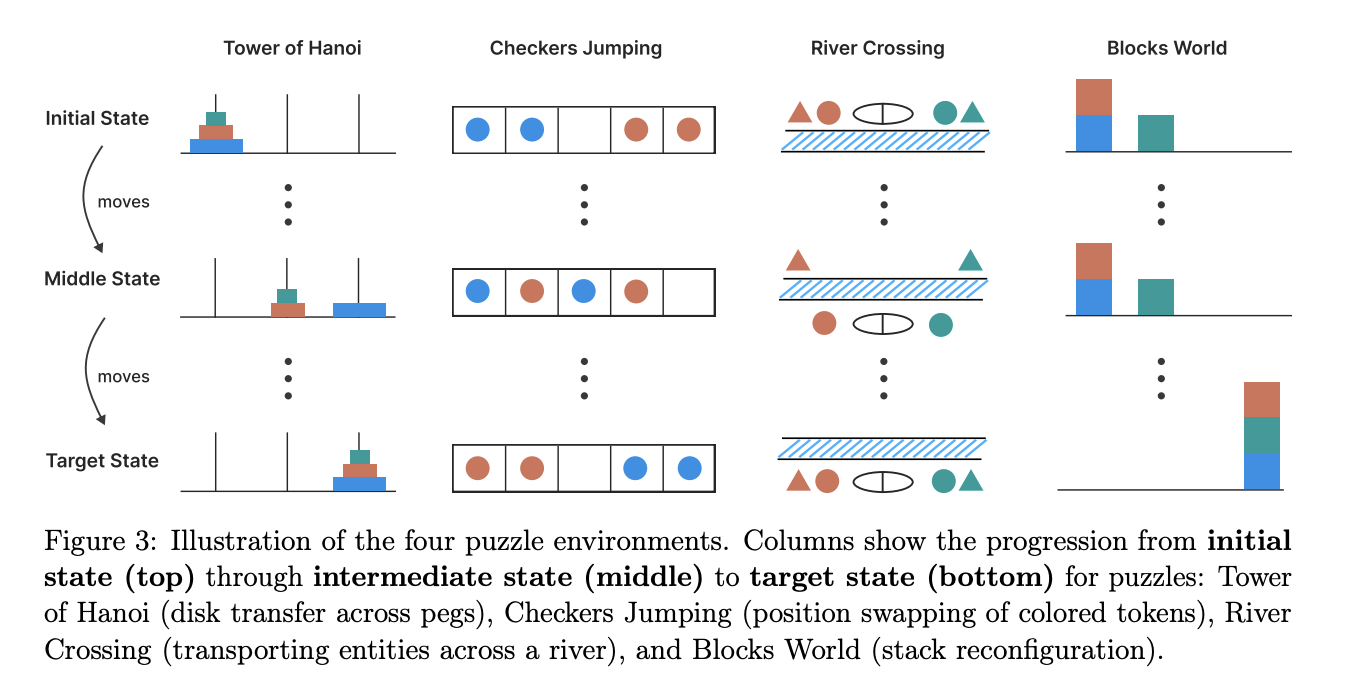
The study utilized four classical puzzles to evaluate the models:
Tower of Hanoi – canonical recursive planning with an exponential optimal length.
Checker Jumping – linear board requiring quadratic optimal length; forward-only moves enforce search.
River Crossing – a generalized “missionaries & cannibals” scenario that introduces safety constraints and boat capacity.
Blocks World – a symbolic AI benchmark requiring temporary unstacking and restacking.
For each puzzle, the authors constructed a deterministic simulator. They replay every intermediate move generated by the model. Illegal moves immediately flag an error, yielding far richer diagnostics than a binary right/wrong assessment on a single final token.
Three Distinct Performance Zone
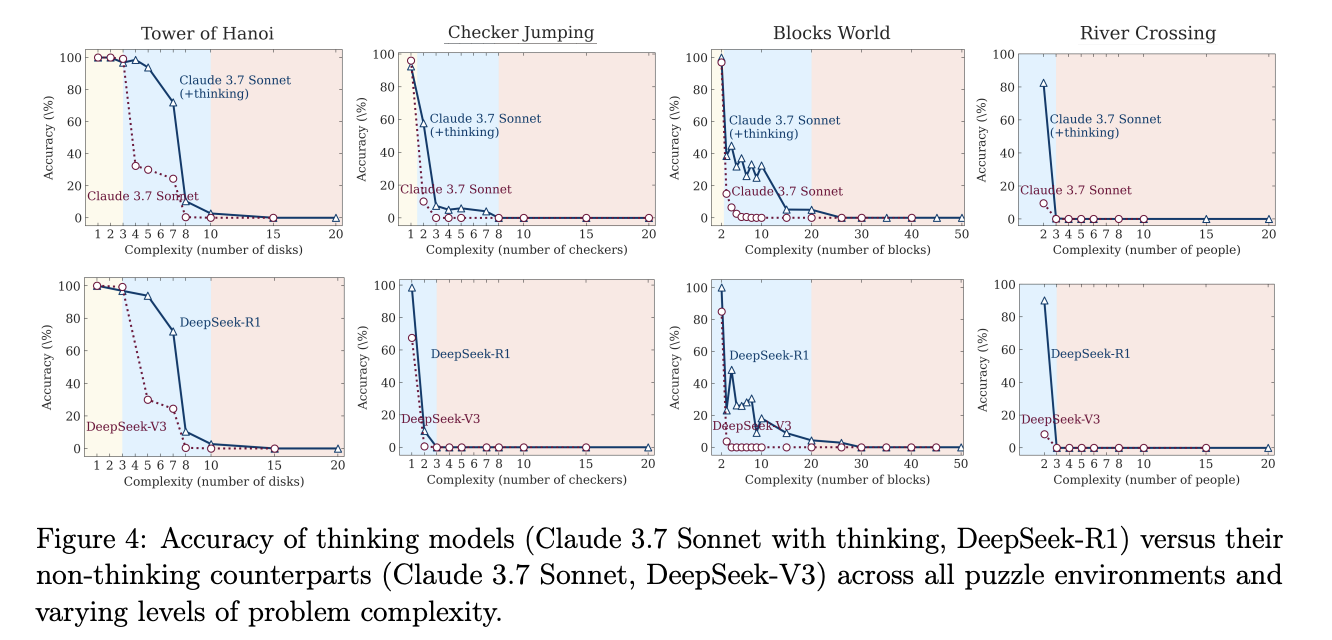
Zone 1: Easy Street
What happens: A tiny Tower of Hanoi (two disks) or checker line (two per color).
Model behavior: The regular no-thinking LLM outperforms the LRM, being faster, using fewer tokens, and achieving higher accuracy
Zone 2: The Sweet Spot
What happens: Add a couple more disks or blocks. Suddenly, chain-of-thought reasoning helps. LRMs inch ahead, being more accurate but at a token cost of 3-10 times.
Zone 3: The Cliff of Doom
What happens: Push complexity one click further. Accuracy for both versions plummets to near-zero. Shockingly, the LRM’s thinking trace actually gets shorter right before it fails completely.
Open Questions for Future Research
Can LRMs be trained to persist rather than truncate near the complexity cliff? —This could reduce sudden failure modes, which is critical for safety-sensitive deployments.
How can we fuse symbolic executors with neural reasoning at runtime without brittle switching? —This method might combine long-horizon precision with flexible pattern matching.
Concluding Appraisal
Shojaee et al. deliver a meticulous empirical study on contemporary “thinking” LLMs. Their controllable-puzzle methodology surfaces nuanced behaviors. The core finding—that reasoning benefits are sandwiched between costs at the low end and collapse at the higher end—should temper exuberant marketing. It also must inform any engineering roadmap leaning on chains of thought.
In summary, this study doesn’t dethrone LRMs. However, it demystifies them. Reasoning improvements are real but fragile, contingent, and bounded. Introspection alone will not elevate today’s models to generalized problem solvers.
Link to article: https://machinelearning.apple.com/research/illusion-of-thinking